

Spark Streaming….
Why Spark Streaming
Many important applications must process large streams of live data and provide results in near-real-time
- Social network trends
- Website statistics
- Intrusion detection systems etc
Requires low latencies for faster processing
What is Spark Streaming
Framework for large scale stream processing
- Scales to 100s of nodes
- Can achieve second scale latencies
- Integrates with Spark’s batch and interactive processing
- Provides a simple batch-like API for implementing complex algorithm
- Can absorb live data streams from Kafka, Flume, ZeroMQ, etc.
Framework for Spark Streaming

Drawbacks of Spark Streaming
- Handling state for long time and efficiently is a challenge in these systems
- Lambda architecture forces the duplication of efforts in stream and batch
- As the API is limited, doing any kind of complex operation takes lot of effort
- No clear abstractions for handling stream specific interactions like late events, event time, state recovery etc.
Structured Spark Streaming
- In structured streaming, a stream is modelled as an infinite table aka infinite Dataset
- As we are using structured abstraction, it’s called structured streaming API
- All input sources, stream transformations and output sinks modelled as Dataset
- As Dataset is underlying abstraction, stream transformations are represented using SQL and Dataset DSL
Output Modes
- Complete Mode - The entire updated Result Table will be written to the external storage. It is up to the storage connector to decide how to handle writing of the entire table.
- Append Mode - Only the new rows appended in the Result Table since the last trigger will be written to the external storage. This is applicable only on the queries where existing rows in the Result Table are not expected to change.
- Update Mode - Only the rows that were updated in the Result Table since the last trigger will be written to the external storage
Advantages
Handles event time and late data
Fault tolerant semantics using source and sink
Window operations on Event time
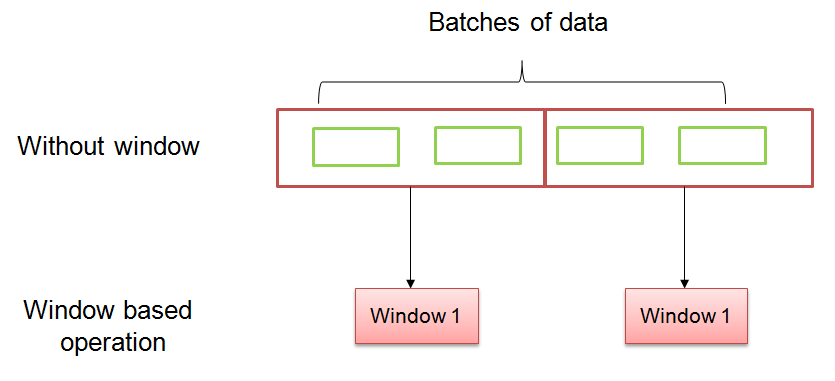
In structured streaming, data is processed window by window instead of batch by batch
This handles out of order data with the help of timestamps attached with original data
Handling late data using watermarking
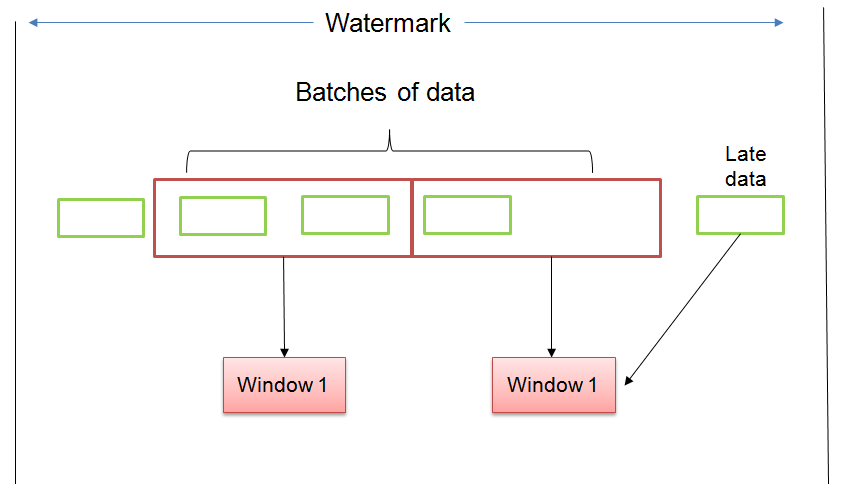
Watermark tracks a point in time before which it is assumed no more late events are supposed to arrive
It handles late data
Joins
Spark supports the following different types of joins
- Static - Static : Inner, left outer, right outer and full outer. All are supported.
- Stream joins with static data : Only inner joins are supported
- Stream-Stream joins : Full outer join is not supported
We will do a deeper dive into stream stream joins in the following slides
Stream Stream - Inner Joins
Simple inner join - Need to buffer all past events as state, a match can come on the other stream any time in the future . This can be time consuming.
Inner join with watermark and time constraints – Time constraints need to be provided so that buffered events can be dropped. We take the example of ad monetisation.
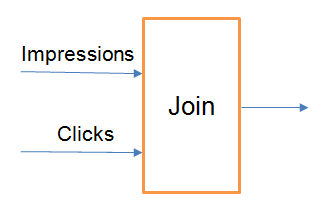
We need 3 watermarks in total. One for each stream, and third for associating each click with impression. As, its not necessary that a user will click on the ad as soon as it appears.
Outer Joins
Time constraints and watermarks are necessary for left, outer and right joins
In case of right outer join, its necessary for us to give a watermark for the left stream, vice versa for left outer join.
Overview of Stream-Stream Joins
- Inner – Optional to specify watermark on both sides + time constraints for state cleanup
- Left Outer – Watermark must be specified on the right + time constraints for correct results, optionally specify watermark on left for all state cleanup
- Right Outer – Watermark must be specified on the left + time constraints for correct results, optionally specify watermark on right for all state cleanup
- Full Outer - Not supported
About the author
Sonali Patro completed her BTech in Computer Science from NIT Rourkela in 2018. She has been working as a Data Engineer in Whiteklay since july 2018.
